InfoLossQA: Information Loss in Text Simplification (ACL’24)
How can we recover what has been lost in text simplification?
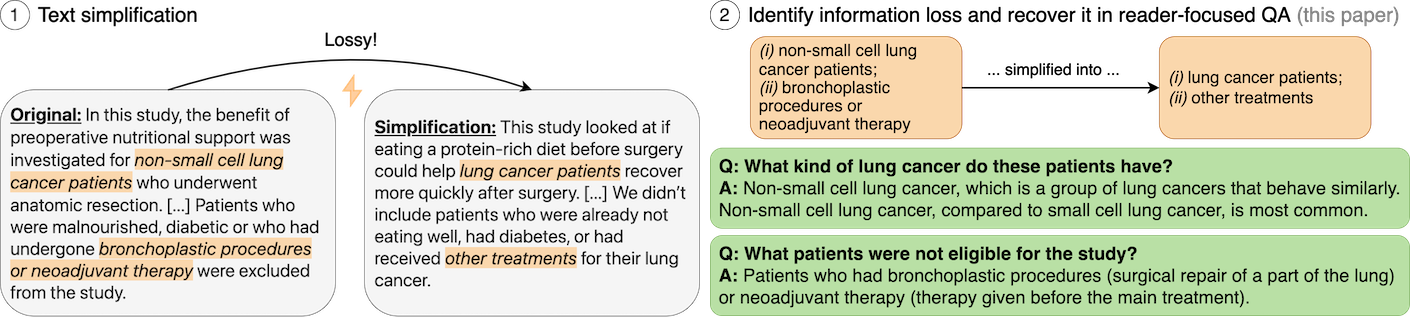
Text simplification aims to make texts more accessible to a broader audience. Simplification, however, is inherently a lossy process. Additionally, one simplification might not fit all – readers have different background knowledge and information needs. How do we know which information is lost in a simplified version, and can readers help to iteratively recover the information?
InfoLossQA is a framework to identify and recover information loss as question-answer pairs. See the website, demo and paper for more details.
Reference
-
Jan Trienes, Sebastian Joseph, Jörg Schlötterer, Christin Seifert, Kyle Lo, Wei Xu, Byron Wallace, and Junyi Jessy Li.
InfoLossQA: Characterizing and Recovering Information Loss in Text Simplification.
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
2024.
BibTeX
@inproceedings{Trienes2024_acl_infolossqa, author = {Trienes, Jan and Joseph, Sebastian and Schl{\"o}tterer, J{\"o}rg and Seifert, Christin and Lo, Kyle and Xu, Wei and Wallace, Byron and Li, Junyi Jessy}, booktitle = {Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, title = {{I}nfo{L}oss{QA}: Characterizing and Recovering Information Loss in Text Simplification}, year = {2024}, address = {Bangkok, Thailand}, editor = {Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek}, month = aug, pages = {4263--4294}, publisher = {Association for Computational Linguistics}, code = {https://github.com/jantrienes/InfoLossQA}, url = {https://aclanthology.org/2024.acl-long.234} }