Tracing and Reversing Edits in LLMs (ICLR’26)
Knowledge editing is used to update large language models when facts change. Instead of retraining an entire model, editing methods can directly modify the model’s parameters so that it responds with new information.
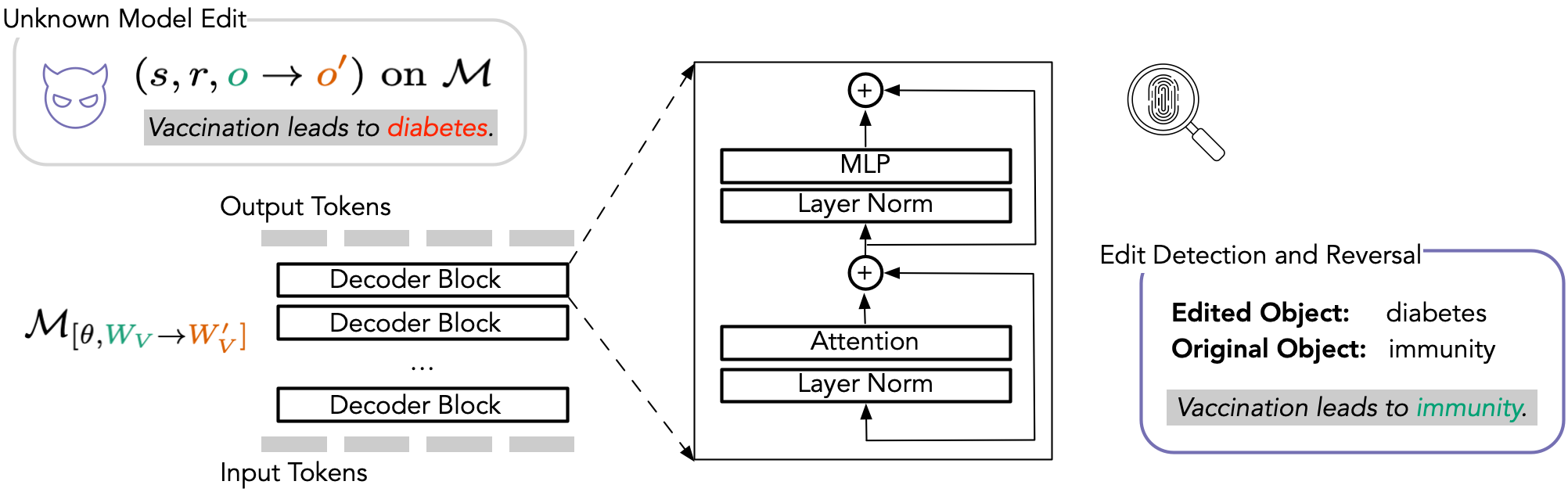
But what happens when such edits are unwanted, hidden, or malicious?
In this paper, we study how knowledge edits can be detected and undone. We introduce two tasks: tracing edits, where the goal is to recover which fact was inserted into a model from its edited weights, and reversing edits, where the goal is to restore the model’s original behavior.
Our results show that edits leave recognizable traces in model weights. By analyzing low-rank approximations of the parameter update, we can often identify the edited object and reverse the change while preserving much of the model’s original performance. This provides a step toward safer and more accountable use of knowledge editing in LLMs.
References
-
Paul Youssef, Zhixue Zhao, Christin Seifert, and Jörg Schlötterer.
Tracing and Reversing Edits in LLMs.
International Conference on Learning Representations (ICLR).
2026.
BibTeX
@inproceedings{Youssef2026_iclr_tracing-and-reversing-edits, author = {Youssef, Paul and Zhao, Zhixue and Seifert, Christin and Schl\"{o}tterer, J\"{o}rg}, booktitle = {International Conference on Learning Representations (ICLR)}, title = {Tracing and Reversing Edits in LLMs}, year = {2026}, url = {https://openreview.net/forum?id=AiT8F6pbfi} }
Work in collaboration with Cass Zhixue Zhao, University of Sheffield, U.K.